Google Special Report: Google's Unindexed URLs
Data from March 7, 2002. Google's Unindexed URLs: An ExampleThis page gives an example of Google's unindexed Web pages and how they look in the results list. As of Dec. 2001, Google says that about 500 million of its 2 billion records are unindexed Web documents. These are URLs for Web pages (or for other file types such as PDF or PowerPoint files) which Google has not crawled and indexed. The screen shot below is an example from March 7, 2002.
How to Identify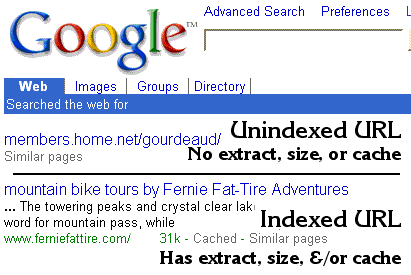
The unindexed URLs are easy to spot when the occasionally appear in Google's results. They have all the following characteristics:
If they are just missing the extract and/or the cached copy, they have probably been indexed. Only the ones missing all three have not been fully indexed. Types of OrphansSo what are these orphans of Google? They may be any of the following kinds of pages.
What is Indexed?These orphans are not completely unindexed. Unlike the bulk of the records in Google, the text of the pages themselves has not been indexed. But there are a few ways in which they are indexed and from which then can be pulled up.
Other than those two items, nothing else is indexed on those pages. So they will not appear very often. For more details on the composition of Google's Web database, see my Google Database Components page.
|

|
A Notess.com Web Site ©1999-2006 by Greg R. , all rights reserved |
Search Engine Showdown Greg's Writings Greg's Presentations |